- «Флешка» за $80 превращает ПК в систему с искусственным интеллектом. Видео
- Компактный нейронный сопроцессор
- Особенности конструкции
- Области применения
- Ограничения
- Использование Intel Movidius для нейронных сетей
- Введение
- Вычислительные мощности устройства
- Приступим к установке и запуску первой программы на NCS
- Что нам понадобится
- Подготовка
- Запустим пример
- Заключение
- Movidius Neural Compute Stick — искуственный разум на флешке
- Робот-танк на Raspberry Pi с Intel Neural Computer Stick 2
- Intel NCS
- Нейросети на NCS
- Инициализировать девайс
- Загрузить модель
- Запустить расчет
- Однопроцессность
- Сегментация OpenVino
- Классификация направлений
- Распознавание объектов
- Классификация картинок
- Заключение
«Флешка» за $80 превращает ПК в систему с искусственным интеллектом. Видео
Компактный нейронный сопроцессор
Компания Movidius, принадлежащая Intel и занимающаяся разработкой визуальных процессоров для интернета вещей, представила миниатюрное компактное устройство Neural Compute Stick. Новинка позиционируется как вычислительный сопроцессор с функциональностью искусственного интеллекта, позволяющий добавить возможность машинного обучения подключенному ПК простым подключением к порту USB.
Ключевая особенность устройства заключается в том, что для процесса машинного обучения или развертывания новой нейронной сети с применением Neural Compute Stick не требуется подключение к интернету: USB-сопроцессор функционирует совершенно автономно.
В сентябре 2016 г. компания Movidius была приобретена Intel за неназванную сумму. По итогам сделки в Intel объявили о планах использовать технологии Movidius при разработке устройств интернета вещей, дополненной, виртуальной и совмещенной реальности, таких как роботах, дронах, автоматических цифровых камерах безопасности и т.д.
Впервые USB-сопроцессор Neural Compute Stick был представлен в качестве прототипа под рабочим названием Fathom в апреле 2016 г. – тогда еще независимой компанией Movidius. Некоторое время после приобретения компании новости о разработках Movidius исчезли со страниц новостных сайтов. Теперь Neural Compute Stick коммерциализирован и официально поступает в продажу, однако технологическая идея устройства претерпела минимальные изменения по сравнению с Fathom.

Устройство Neural Compute Stick выполнено на базе точно такого же процессора, который используется во множестве устройств с машинным зрением — например, автономном дроне DJI. Потребителю или производителю техники, желающему усилить возможности искусственного интеллекта своей системы, достаточно подключить один или несколько сопроцессоров Neural Compute Stick к порту (портам) USB.
Особенности конструкции
Compute Stick базируется на визуальном чипе (Vision Processing Unit, или VPU) под названием Myriad 2, который представляет собой сверхэкономичный процессор с потреблением не более 1 Вт. Чип Myriad 2 базируется на 12 параллельно работающих 128-битных векторных VLIW-ядрах с архитектурой SHAVE, работающих с алгоритмами машинного зрения, такими как детектирование объектов или распознавание лиц.

Процессор Myriad 2 поддерживает 16/32-битные вычисления с плавающей запятой и 8/16/32-битные целочисленные операции. Чип оснащен 2 МБ распределенной памяти, подсистемой памяти с производительностью до 400 Гбит/с и кэш-памятью L2 объемом 256 КБ. Номинальная тактовая частота чипа составляет 600 МГц при питающем напряжении 0,9 В. Производится Myriad 2 с соблюдением норм 28 нм технологического процесса.
Согласно данным официальных представителей Movidius, чип обеспечивает производительность на уровне более чем 100 гигафлопс и способен нативно запускать нейронные сети на базе фреймворка Caffe.
Neural Compute Stick оснащен скоростным портом USB 3.0 Type-A, его габариты составляют 72,5 х 27 х 14 мм. Минимальные требования для запуска устройства на хост-системе с процессором архитектуры x86_64 составляют: ОС Ubuntu версии 16.04, порт USB 2.0 (лучше USB 3.0), 1 ГБ оперативной памяти и 4 ГБ свободного дискового пространства.

Основное визуальное отличие USB-сопроцессора Neural Compute Stick от своего прототипа Fathom заключается в том, что новая розничная версия выполнена в корпусе из алюминия (прототип был представлен в пластике).

USB-сопроцессор Neural Compute Stick доступен для заказа по цене $79 (Fathom в свое время предлагался по $99.
Области применения
USB-сопроцессор Neural Compute Stick может пригодиться разработчикам систем искусственного интеллекта, которые могут его использовать в качестве акселератора уже имеющихся ПК для локального ускорения процесса машинного обучения или создания новых нейронных сетей. По данным Movidius, несколько USB-сопроцессоров Neural Compute Stick, подключенных к системе, увеличивают ее производительность практически линейно.

Compute Stick также может заинтересовать компании, планирующие выпускать собственные продукты с возможностью оперативного локального формирования нейронных сетей с помощью простого подключения USB-совместимого устройства.
Ограничения
Устройства класса Compute Stick имеют определенные ограничения по масштабу вычислительной мощности, не всегда масштабируемые на большие проекты.
Поэтому для корпоративных профильных систем – таких как, например, сеть камер безопасности с искусственным интеллектом, или большие нейронные сети, компаниям будет выгоднее приобрести специализированные процессоры машинного зрения, усилить вычислительную мощность графическими картами или арендовать дополнительные вычислительные ресурсы у облачных провайдеров.
Источник
Использование Intel Movidius для нейронных сетей
Введение
Мы занимаемся разработкой глубоких нейронных сетей для анализа фото, видео и текстов. В прошлом месяце мы купили для одного из проектов очень интересную штуковину:
Intel Movidius Neural Compute Stick. 
Это специализированное устройство для нейросетевых вычислений. По сути, внешняя видеокарточка, заточенная под нейронные сети, очень компактная и недорогая (
$83). Первыми впечатлениями от работы с Movidius’ом мы и хотим поделиться. Всех заинтересовавшихся прошу под кат.
Вычислительные мощности устройства
В плане вычислений нейронки чрезвычайно прожорливы: для их обучения нужны GPU, а для использования в реальных задачах – тоже GPU или мощные CPU. Movidius NCS позволяет использовать глубокие нейросети на устройствах, которые были первоначально на это не рассчитаны, например: Raspberry Pi, DJI Phantom 4, DJI Spark. Речь идёт только про этап предсказания (inference заранее обученной сети): обучение нейросетей на Movidius пока что не поддерживается.
Производительность чипа – около 100 гигафлопс, 10^9 FLOPS, (это примерно соответствует уровню топовых суперкомпьютеров начала 90ых, сейчас это порядка сотен петафлопс, 10^15).
Для справки: FLOPS – это количество вычислительных операций или инструкций, выполняемых над операндами с плавающей точкой (FP) в секунду. Для углубления в тему советую интеловскую статью.
Железка построена на базе чипа Myriad 2. В конфигурацию Myriad 2 входит 12 специализированных программируемых векторных процессоров. Компоненты SoC подключены к высокоскоростному внутреннему соединению, работающему с минимальными задержками. Myriad 2 позиционируется как сопроцессор совместно с процессором приложений в мобильных устройствах, или как автономный процессор в устройствах носимой или встраиваемой электроники.

Сам процессор Myriad 2
Ну а в форм-факторе флешки (Neural Compute Stick) его можно использовать для встраивания нейросетей в беспилотники, например, вместе с Raspberry Pi.
Приступим к установке и запуску первой программы на NCS
Что нам понадобится
Подготовка
Подключаем Movidius в разъем USB 3.0. Далее пишем в консоли:
Эти команды установят:
- NCS Libraries → /usr/local/lib
- NCS Toolkit binaries → /usr/local/bin
- NCS Include files → /usr/local/include
- NCS Python API → /opt/movidius
А также добавят путь к python-либе Мовидиуса в PYTHONPATH.
Запустим пример
В той же папке выполним команду для построения примеров:
Чтобы подготовить стандартный пример – обученную на ImageNet реализацию inception_v1 – выполним следующие команды:
Последняя команда использует описание сетки и уже обученные веса и компилирует бинарный граф, который мы можем потом уже запустить на Myriad 2 VPU.
Теперь мы запустим тестовый скрипт run.py. Коротко расскажу, что происходит в скрипте в целом (некоторые части скрипта опущены):
Когда мы собирали пример, мы вводили в консоль команду make all, после которой в консоль выводилась полезная информация, например, можно увидеть, как быстро данные проходят через каждый слой сети с помощью Detailed Per Layer Profile. Полезная для отладки и оптимизации штука.
Тестовая картинка загрузится на NCS, пройдёт через Inception, и в консоли отобразится результат распознавания (вероятностное распределение по 1000+1 категории датасета ImageNet).
99% уверенностью полагает, что на картинке компьютерная мышь (благодаря нашей подсказке 🙂 ), на втором месте с близкой к 0% уверенности – модем, и так далее. Сетка права, так что поздравляем вас с первой нейронкой, успешно запущенной на этом устройстве!
Заключение
В конце хотелось бы перечислить главные достоинства и недостатки устройства.
Сперва плохие новости:
- Устройство официально поддерживает работу только с Raspbian OS или Ubuntu 16.04 LTS.
- Устройство и его SDK на данный момент поддерживают только файлы с весами нейросетей в формате Caffe и Tensorflow.
- На устройстве можно делать только предсказания (inference), а обучать модели нельзя.
Хорошие новости:
- Вы можете запускать нейронки на Raspberry Pi!
- Очень простой API на python/C.
- Низкая потребляемая мощность (1 Вт), устройство питается от USB.
- Очень быстрый для такого компактного устройства: например, препроцессинг фотографии
800х800 и прогон её через Inception_v1 занимают
120-130 миллисекунд.

Так Intel предлагает использовать Мовидиусы для ускорения вычислений
Само собой, у данного устройства есть аналоги.
Один из них – и пока самый многообещающий – это Gyrfalcon Technology Laceli, имеющий производительность в 28 раз больше, а энергетическую эффективность в 90 раз выше. Единственное препятствие для покупки – это то, что устройство ещё не вышло на рынок.
Еще один конкурент, который давно присутствует на рынке – это NVIDIA Jetson TX2. Отличия:
- Очень разные ценовые категории (559$ против 83$)
- Разные мощности (два ядра CPU на архитектуре Denver 2, четыре ядра ARM Cortex A57 и 256-ядерный Pascal GPU против одного Myriad 2)
- Разный форм-фактор: Jetson гораздо больше, NCS компактный
- Оба устройства решают одну и ту же задачу – задачу внедрения нейронок на борт чего-либо: автомобиля, беспилотника и пр.
Если интересно, напишем в ближайшем будущем еще одну статью про использование Jetson TX2 для нейронных сетей. Спасибо за внимание и хорошего дня)
P. S. Intel объявил о старте конкурса по оптимизации нейросетей для Intel Movidius Neural Compute Stick. Регистрация до 26 января, окончание конкурса – 15 марта.
Источник
Movidius Neural Compute Stick — искуственный разум на флешке
20 июля Intel объявила о выпуске Movidius Neural Compute Stick — миниатюрного ускорителя для решений, связанных с искусственным интеллектом, нейронными сетями и глубоким изучением. Выполненный в формате USB-флешки, ускоритель позволит реализовывать элементы искусственного разума на самых разнообразных платформах и устройствах, что, думаю, по достоинству оценят любители робототехники, летающих аппаратов, а также разработчики разнообразных интеллектуальных устройств.

Компания Movidius, приобретенная Intel в конце прошлого года, специализируется на разработке аппаратных и программных компонентов искусственного разума. Основой Neural Compute Stick является разработанный Movidius Vision Processing Unit (VPU) Myriad 2 — специализированное вычислительное устройство, обладающее малым энергопотреблением (всего 1 Ватт), но при этом приличной производительностью — 100 Гигафлопс. Такие характеристики позволяют Movidius Neural Compute Stick работать полностью автономно, без доступа к интернету и облачным сервисам.
Movidius Neural Compute Stick позволяет быстро и удобно прототипировать, профилировать и настраивать потоки в сверточных нейронных сетях (Convolutional Neural Network, CNN) для нужд конечных приложений. Для разработчиков создан специализированный Neural Compute SDK. Таким образом, устройство, оснащенное USB-портом может стать интеллектуальным, автономным и самообучающимся.
Ускоритель доступен для заказа по цене $79.
Источник
Робот-танк на Raspberry Pi с Intel Neural Computer Stick 2
Вот и наступил новый этап в развии Raspberry-танка.
В предыдущей серии оказалось, что семантическая сегментация из коробки не по зубам Raspberry.
Мозговой штурм и комментарии позволили определить следующие направления развития:
- обучить собственную E-net сеть под нужный размер картинок
- передать запуск нейросети с самой Raspberry на специальную железку, из которых наиболее часто упоминался Intel Movidius (он же Neural Compute Stick aka NCS).
Приделать к роботу новую железку — это же самое интересное в роботехнике, поэтому кропотливая работа по обучению нейросети оказалась отложенной до лучших времен.
Несколько дней — и интеловская чудо-железка у меня в руках.
Она довольно большая, и в нижний USB разъем малинки ее не воткнешь. Учитывая, что правые USB порты были заслонены штативом камеры, а верхний левый занят GPS модулем, вариантов оставалось не то, чтобы много.
В итоге, GPS был посажен на кабель, переведен вниз, и кабель обернут вокруг штатива, а на его место зашел NCS.
На этом hardware часть была завершена.

Intel NCS
Интел недавно выпустил вторую версию NCS, причем API оказался полностью несовместим с предыдущей версией, о чем пользователи излили немало боли в интернете.
Как следствие, вся база знаний о предыдущей версии в настоящее время является просто информационным мусором.
В новой редакции предлагается фреймворк OpenVino, который включает в себя OpenCV и много всякого другого, в том числе и различные инструменты для работы с нейросетями.
Вот несколько вводных статей по NCS2 и OpenVino:
Интел изначально сделал поддержку Raspbian, так что танцевать с бубном не пришлось.
Вводный документ оказался также весьма четким и установка фреймворка OpenVino никаких проблем не вызвала.
Приятным бонусом оказалось, что в OpenVino входит OpenCV 4.1, это экономит время, так как предыдущие версии OpenCV мне пришлось собирать на Raspberry самостоятельно.
Вот как выглядит NCS2 сам по себе:

Дальше оказалось интереснее.
NCS поддерживает только свой собственный формат нейросетей, а Интел предоставляет инструмент Model Optimizer в составе OpenVino для конвертации графов самых популярных фреймворков: Tensorflow, Caffe, Torch. Подробнее про это будет дальше.
Кроме того, Интел также предоставляет model zoo — набор готовых моделей на многие случаи жизни.
Среди них были две модели для дорожной сегментации:
Нейросети на NCS
Для того, чтобы запустить нейросеть на девайсе, надо сделать несколько шагов.
Инициализировать девайс
Название MYRIAD, идея плагина и динамическая загрузка его либы, путь к которой надо указать в программе — явно тянутся из темного прошлого.
Загрузить модель
Дальше надо загрузить модель на девайс.
Это тяжелая операция. Та небольшая модель, которую я использовал для сегментации, грузится порядка 15 секунд.
Хорошие новости в том, что загружать модель нужно только раз и можно загрузить несколько моделей.
Запустить расчет
Теперь модель можно использовать.
Однопроцессность
Внезапно оказалось, что нельзя использовать NCS из двух разных процессов одновременно.
Тот кто опоздал, не может загрузить модель:
Ни Гугл, ни форум поддержки Интела не позволили понять, в чем же дело — или девайс и правда эксклюзивный или я просто не умею его готовить.
Сегментация OpenVino
Как уже говорилось, из коробки OpenVino предоставляет модель дорожной сегментации и примеры.
Результаты тестов несколько противоречивы. Иногда распознается криво, но в большинстве нормально.
Enet работал лучше, но запустить Enet под NCS надо еще постараться, так что попробуем с тем что есть.

Что интересно, узнать больше о модели из OpenVino и переобучить ее не так то просто.
Пользователи интересуются, но человек из Интела строго сказал, что код и данные модели закрыты, а желающие могут взять подобную нейросеть на PyTorch, обучить, конвертировать и использовать.
По скорости преимущество очень значительно:
Если у Enet сегментация занимала 6 секунд, то у этой модели на обработку одной картинки уходило 0.8 секунд (при этом 14 секунд занимала загрузка модели на девайс, но это делается единовременно).
Классификация направлений
Для принятие решений о направлении движения танк использует простую нейросеть, как описано в соотвествующей статье.
Нейросеть обучена на Keras и работает на Raspberry через Tensorflow, который имеет встроенный адаптер для этого формата.
Модель очень простая и даже на Raspberry показывает приемлемые по скорости результаты.
(0.35 секунд на картинку).
Тем не менее, имея интеловскую железку, можно рассчитывать добиться лучших результатов.
Среди форматов, которые принимает интеловский Model Optimizer для конвертации, есть Tensorflow, но нет Keras.
Преобразование Keras в TF вещь довольно популярная, материала на эту тему хватает, я руководствовался этой статьей.
У этого же автора есть более обширная статья, как раз на тему, как модель Keras запустить на OpenVino.
В общем, скомпилировав источники, я получил такой скрипт для преобразования модели Keras в TF:
Получившуюся TF-модель дальше перегоняем в OpenVino формат:
Тесты показали, что классификация картинки проходит за 0.007 секунд.
Такой результат очень радует.
Все обученные модели (Keras, TF, OpenVino) также выложены на гитхаб.
Распознавание объектов
Задача сегментации — не единственная, которую приходится решать роботу в своей нелегкой жизни.
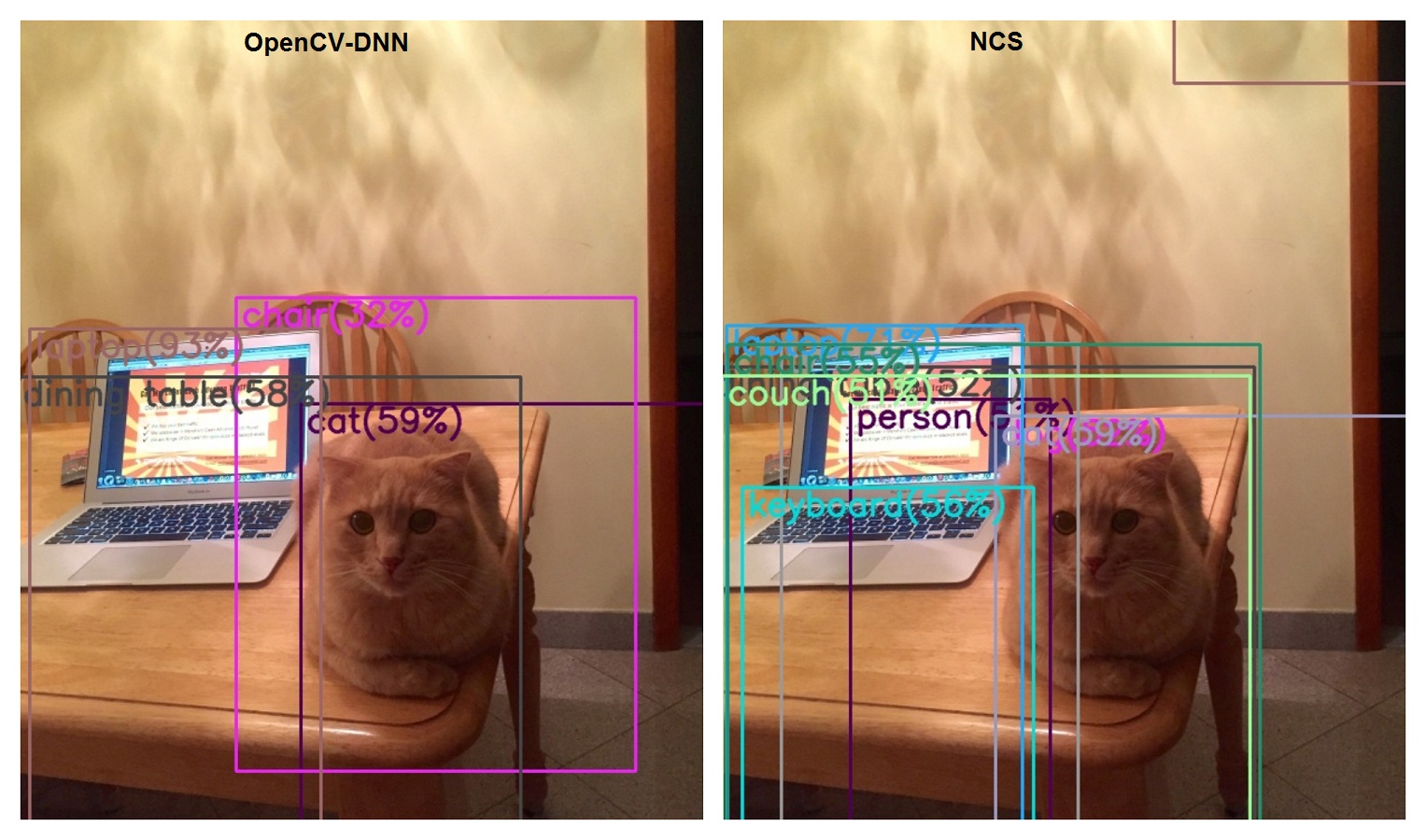
В начале был детектор кота, который потом вырос в универсальный детектор на основе MobileSSD и OpenCV-DNN.
Теперь пришла пора покрутить эту же задачу на NCS.
В интеловском model_zoo достаточно детекторов более узкой специфики на основе MobileSSD, но точный аналог отсутствует.
Тем не менее, эта сеть указана как совместимая в списке поддерживаемых моделей TF.
Что интересно, на момент написания статьи здесь указана версия MobileSSD 2018_01_28.
Однако, читать эту модель OpenCV отказывается:
(Зато мы узнали, что они используют Jenkins).
При этом, конвертация в OpenVino проходит успешно.
Если же попробовать сконвертировать версию Mobile SSD, совместимую с OpenCV-DNN (11_06_2017), то получаем такое:
Как-то так, технически OpenVino и OpenCV-DNN в одной поставке, но несовместимы по версиям используемых нейросетей.
То есть, если хочется использовать одновременно оба подхода, надо тащить две версии MobileSSD.
По скорости сравнение конечно же в пользу NCS: 0.1 секунды против 1.7.
По качеству. (Хотя это вопрос не к NCS, а к эволюции Mobile SSD).
Классификация картинок
Танк умеет классифицировать картинки через Tensorflow, используя Inception на Imagenet.
Причем я использовал Inception 2015-12-05, когда она была еще одна.
Оказалось, я сильно отстал от жизни, ибо ребята из Гугла не даром едят свой хлеб и уже наплодили аж 4 версии!
Но ребята из Интела от них не отстают и все 4 версии поддержали в OpenVino.
Вот статья с описанием различных версий Inception.
Но мы не будем мелочиться, качаем сразу последнюю, четвертую.
Классифицируем картинку с котом и лаптопом на столе.
Запоминаем результаты работы текущей версии:
- laptop, laptop computer 62%
- notebook, notebook computer 11%
- 13 секунд
- где кот?
Теперь читаем инструкцию по конвертацию Inception в OpenVino.
Конвертация проходит успешно, запускаем классификатор на NCS:
- laptop, laptop computer 85%
- notebook, notebook computer 8%
- 0.2 секунды
- кота опять нет
Заключение
Таким образом, все сценарии, требовавшие Tensorflow, были воспроизведены с помощью NCS, и это означает что от использования Tensorflow можно отказаться.
Все таки этот фрейморк тяжеловат для Raspberry.
Скорость, с которой NCS переваривает нейросети позволяет его расширить горизонты его применения.
Есть задачи, которые робот уже делает, например, семантическая сегментация и классификация, но есть и другие вроде объектной сегментации или передачи видео с детектированными объектами в реальном времени. (о чем нельзя было и помыслить на голой Raspberry).
Несколько смущают проблемы с многопроцессностью, но даже если их не удастся решить, то всегда остается выход в виде оборачивания NCS отдельным сервисом.
Источник